Serverless Distributed Decision Forests with AWS Lambda
Within the Wise.io team in GE Digital, we have monthly "edu-hackdays" where the entire tech team spends the entire day trying to learn and implement new promising approaches to some portion of our machine-learning based workflow. In the past, we worked on algorithm hacks and on methods for distributed featurization. Some of what we start those days eventually go into production, but most does not. The main goal (apart from the team building that comes with the fun and pain of all-day hacks) is to create collective knowledge and experience around important components of our stack. Recently we had an edu-hackday on strategies for distributed learning. This post captures (and hopefully provides some motivation for) the work I did at that hackday in April.
Distributed Decision Forests
In constructing a classification or regression model with an ensembles of trees ("decision forests"), learning at the tree level trivially parallelizes so long as the entirety of the dataset is close to each compute unit. The process of building trees with independent random seeds on independent (or memory-shared) copies of the training data should yield models of equal quality as those built sequentially. In principle, parallel learning (and prediction) should strongly scale in the number of trees versus processes (not true, of course, for scaling with respect to the number of data points).
Many popular open-source implementations of decision forests can learn in parallel in multi-core, signal-node environments. For example, Python's scikit-learn leverages joblib to build trees in parallel (multi-threaded or multi-processed). Distributed embarrassingly parallel learning across nodes can be done with dask.distributed. (Distributed implementations in H20 and in Spark/MLlib build single trees across on distributed data based on the MapReduce-based algorithms from Google's MapReduce PLANET paper).
One of the main drawbacks of distributed learning is the need to persist, scale, and maintain clusters of potentially expensive compute resources. For heavily and consistently used clusters in large companies or research environments, these operational expenses (including the people costs) may be economical. But for many for many others, with sporadic learning workloads, the computational and personnel overhead can be a huge burden.
Enter Serverless
The event-driven, asynchronous serverless compute paradigm represents a fundamental departure from the way data is served and processed. Rather than host and manage the oft-idle computational substrate in where the heavily lifting is occasionally done, serverless allows us to leverage lightweight functions on an as-need basis. This pushes management, orchestration, and scaling down to the PaaS layer and allows us to focus almost entirely on functionality and content.
Though there are now many competing offerings, AWS Lambda was the first commercial-scale serverless framework. Since we're an AWS shop (for the most part), for my hack I wanted to see if I could use AWS Lambda to build a serverless distributed decision forest implementation.
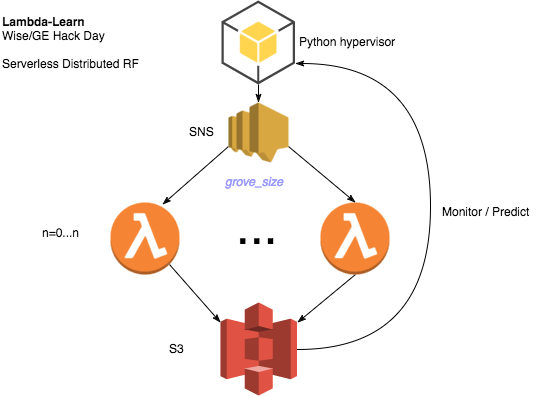
The overall strategy here is pretty simple: each lambda function should generate its own independent random decision tree. While Wise.io has its own proprietary implementation of popular learning algorithms, for this I decided to use scikit-learn to generate trees. A Python script serves as the hypervisor to launch and collect the results from tree building. The idea of the flow is here.
Creating the Lambda Function
One of the main challenges with getting AWS Lambda functions to work is that, while they can run out-of-the-box Python, many non-standard packages cannot be easily imported at runtime. Ryan Brown had a recent post that presented the steps to create a Docker image that emulates the Amazon Linux runtime environment, thereby allowing us to compile third-party Python packages needed to build trees.
Now we need to make the virtual environment that we'll use to upload to AWS:
Next create a Python script main.py and put inside the ve_package/ directory.
There are only a few functions here:
- _save_model_to_s3(): uses joblib to serialize the model and stores it to s3 with a unique name.
- load_data(): here just using sklearn's version of MNIST. But you could pull data from s3 or HBASE here too.
- learn_model(): learns the decision forest model
- handler(): the function that will be called by AWS Lambda
In the handler, we're passing down a random seed. This seed will be propagated from the hypervisior to ensure that each tree is built with its own seed. Rather than have each lambda invocation create one tree, we create small collection of trees (which we call "groves") by setting the parameter n_estimators (=10 by default). So that with m=15 invocations of lambda we get m ⨉ n_estimators = 150 trees in the final forest.
Setting up AWS Lambda, IAM, and SNS
Create a role for your lambda user that will allow it to access S3 (in case you want to have your lambda function access the training data in S3):
| { | |
| "Version": "2012-10-17", | |
| "Statement": [ | |
| { | |
| "Effect": "Allow", | |
| "Action": [ | |
| "logs:CreateLogGroup", | |
| "logs:CreateLogStream", | |
| "logs:PutLogEvents" | |
| ], | |
| "Resource": "arn:aws:logs:*:*:*" | |
| }, | |
| { | |
| "Effect": "Allow", | |
| "Action": [ | |
| "s3:GetObject", | |
| "s3:PutObject", | |
| "s3:ListBucket" | |
| ], | |
| "Resource": [ | |
| "arn:aws:s3:::YOUR-BUCKET-NAME/*" | |
| ] | |
| } | |
| ] | |
| } |
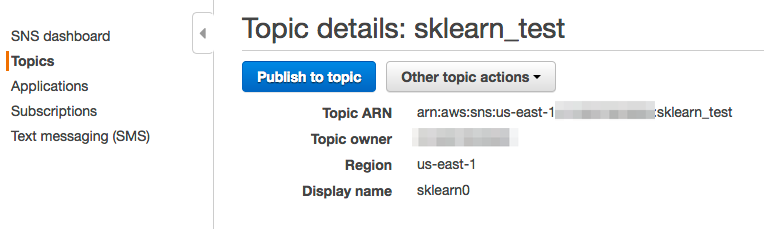
We'll want to invoke our lambda functions via an SNS message. First set up an SNS topic for this project:
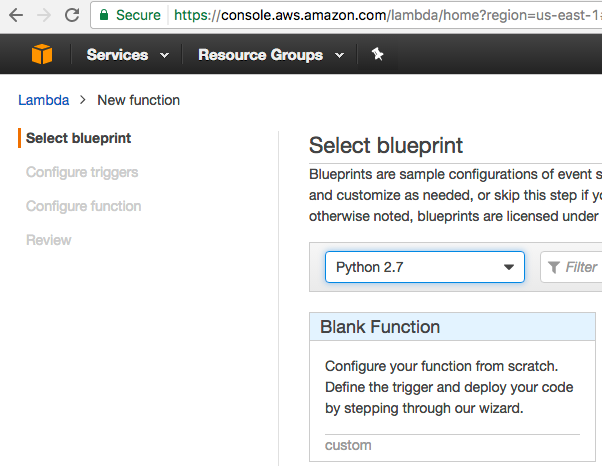
Next, navigate to AWS Lambda and create a blank Python 2.7 function.
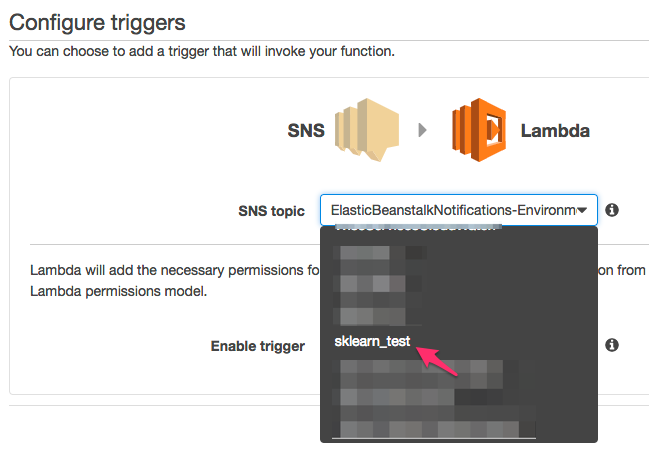
Create an SNS trigger for this lambda function:
Set the handler to be main.handler and then upload the package. To prepare for upload, with main.py inside ve_package:
zip -r ../ve_archive.zip * --exclude \*.pycUpload ve_archive.zip (you can also first upload to S3 and then pull from this S3 key).
Go ahead and test it. You should see an output like:
START RequestId: d4813335-56d1-11e7-8de1-ff2e8b921d75 Version: $LATEST
{'build_id': 'test_m1', 'nest': 10, 'grove_id': 2, 'nrows': 56000, 'seed': 10, 'gamma': 0.8}
Saving model to local file: /tmp/build_test_m1_grove_2.sav
Uploading /tmp/build_test_m1_grove_2.sav --> s3://YOUR-S3-BUCKET/lambda_learn/models/test_m1/grove_2.sav
{('test_m1', 2): 'lambda_learn/models/test_m1/grove_2.sav'}
END RequestId: d4813335-56d1-11e7-8de1-ff2e8b921d75
REPORT RequestId: d4813335-56d1-11e7-8de1-ff2e8b921d75 Duration: 1504.94 ms Billed Duration: 1600 ms Memory Size: 512 MB Max Memory Used: 69 MBNote that it took about 1.3 seconds to build 10 trees on this little MNIST dataset. We also used 69 MB of memory, well under the default cap of 512 MB.
Running and testing a distributed job
We now need a script to invoke a certain number of lambda jobs and then wait for those jobs to complete. After completion, it should assemble the results into a single model and make predictions. This script is in the file lamlearn.py. This can be run as a CLI:
$ python lamlearn.py --help
usage: lamlearn.py [-h] [-g GROVE] [-t TREES] [-p] [-s] namepositional arguments:name model name (e.g. smelly-owl-1)optional arguments:-h, --help show this help message and exit-g GROVE, --grove GROVEgrove size [default=10]-t TREES, --trees TREESn trees total [default=30]-p, --pred predict-s, --s run synchronously
Building a 500-tree decision forest over 50 lambdas and then making a prediction you'd get an output like:
$ python lamlearn.py jsb-blog-run2 -t 500 -p
n_groves: 50{'build_id': 'jsb-blog-run', 'nest': 10, 'seed': 486191, 'grove_id': 0}{'build_id': 'jsb-blog-run', 'nest': 10, 'seed': 451283, 'grove_id': 1}{'build_id': 'jsb-blog-run', 'nest': 10, 'seed': 165158, 'grove_id': 2}....{'build_id': 'jsb-blog-run', 'nest': 10, 'seed': 978124, 'grove_id': 49}triggering 50 groves asynchronouslyWaiting for all the λ's to complete🤑 Completed in 15.740929 sec ... found all 50 groves🤑 time since last λ fired until complete: 15.161692 secThe joblib save files for each grove are in: s3://YOUR-S3-BUCKET/lambda_learn/models/jsb-blog-runPrediction...Getting all the grove models from s3...Merging grove models...RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',max_depth=None, max_features='auto', max_leaf_nodes=None,min_impurity_split=1e-07, min_samples_leaf=1,min_samples_split=2, min_weight_fraction_leaf=0.0,]n_estimators=30, n_jobs=1, oob_score=False, random_state=None,verbose=0, warm_start=False)Score: 1.000000
Caveats and Next Steps
The lambda learner and assembler are obviously just toy examples. You obviously shouldn't be using this in production (or even for exploratory analysis). I've taken some short cuts here. For example, you'll notice in main.py that we learn over the entire dataset. If you wanted a good measure of the accuracy on unseen data, you would obviously want to have consistent train-test splits across each lambda function. You'll also notice the rather clunky way of concatinating grove-level models into a single monolithic model. It would be more elegant (and much more fast) to build a lambda predict capability that invokes all the grove-level models in individual lambda functions and then aggregates the votes from each grove accordingly. Instead of building a distributed forest you could instead imagine using serverless to do random or grid searches over decision forest hyperparameters; that is, allow each lambda to build an entire forest but with different hyperparameters of the model.
The good news is that running this few number of lambdas is basically free on AWS (for now), whereas it might have cost us a few dollars build models of this size with a reasonable AWS machine should we have built models the not serveless way. However, we are much more limited in serverless in our ability to build models that take a long time or take too much memory. At present, we can allocate only up to 1.536 GB per lambda and each job must complete within 5 minutes. So for much larger datasets the time to read data from S3 (or other stores) may be a signficant bottleneck and the learner would need to be memory efficient. By default only 1000 lambdas can be running concurrently so if we built REALLY large forests with small groves, or were running multiple learning jobs simultaneously, we could get throttled here as well.
I did not perform any scientific scaling tests, but did note that a 5000-tree forest built in 25 seconds was about 3 times slower than a 150-tree forest. My hunch is that this has more to do with the overheads in firing off SNS messages from my two-core laptop over a so-so connection than with anything fundamental on the AWS side.
The setup time for lambda is not insignificant and adding 3rd party packages is indeed a pain (debugging is also a real pain). Projects like PyWren, headed by Eric Jonas, from UC Berkeley's RISElab, aim to make set up and execution of serverless jobs much more straightforward. Eric's paper also shows a number of scaling and throughput tests.
Originally posted at wise.io/tech blog … see the archive.org link.
)
Joshua Bloom
Professor of Astronomy
Astrophysics Prof at UC Berkeley, former Wise.io cofounder (acquired by GE); Previous Department Chair; Inventor; Dad, Tennis everything. Anti #TransparentMoon. Check out his group activities at ml4science.org and art exhibition CuratingAI.art (Spring 2024).