Thoughts following the 2015 “Text By The Bay” Conference
The first "
Text By the Bay” conference, a new
natural language processing (NLP) event from the “
Scala bythebay” organizers, just wrapped up tonight. In bringing together practitioners and theorists from academia and industry I’d call it a success, save one significant and glaring problem.
1. word2vec and doc2vec appear to be pervasive
Mikolov et al.’s work on embedding words as real-numbered vectors using a skip-gram, negative-sampling model (word2vec code) was mentioned in nearly every talk I attended. Either companies are using various word2vec implementations directly or they are building diffs off of the basic framework. Trained on large corpora, the vector representations encode concepts in a large dimensional space (usually 200-300 dim). Beyond the “king - man = queen - woman” analogy party trick, such embeddings are finding real-world applications throughout NLP. For example, Mike Tamir ("Classifying Text without (many) Labels"; slide shown below), discussed how he is using the average representation over entire docs as features for text classification, out-performing other bag-of-words (BoW) techniques by a large measure with heavily imbalanced classes. Marek Kolodziej ("Unsupervised NLP Tutorial using Apache Spark”) gave a wonderful talk about the long history of concept embeddings along with technical details of most of the salient papers. Chris Moody ("A Word is Worth a Thousand Vectors”) showed how word2vec was being used in conjunction with topic modeling for improved recommendation over standard cohort analysis. He also ended his talk about how word2vec can be extended beyond NLP to machine translation and graph analysis.
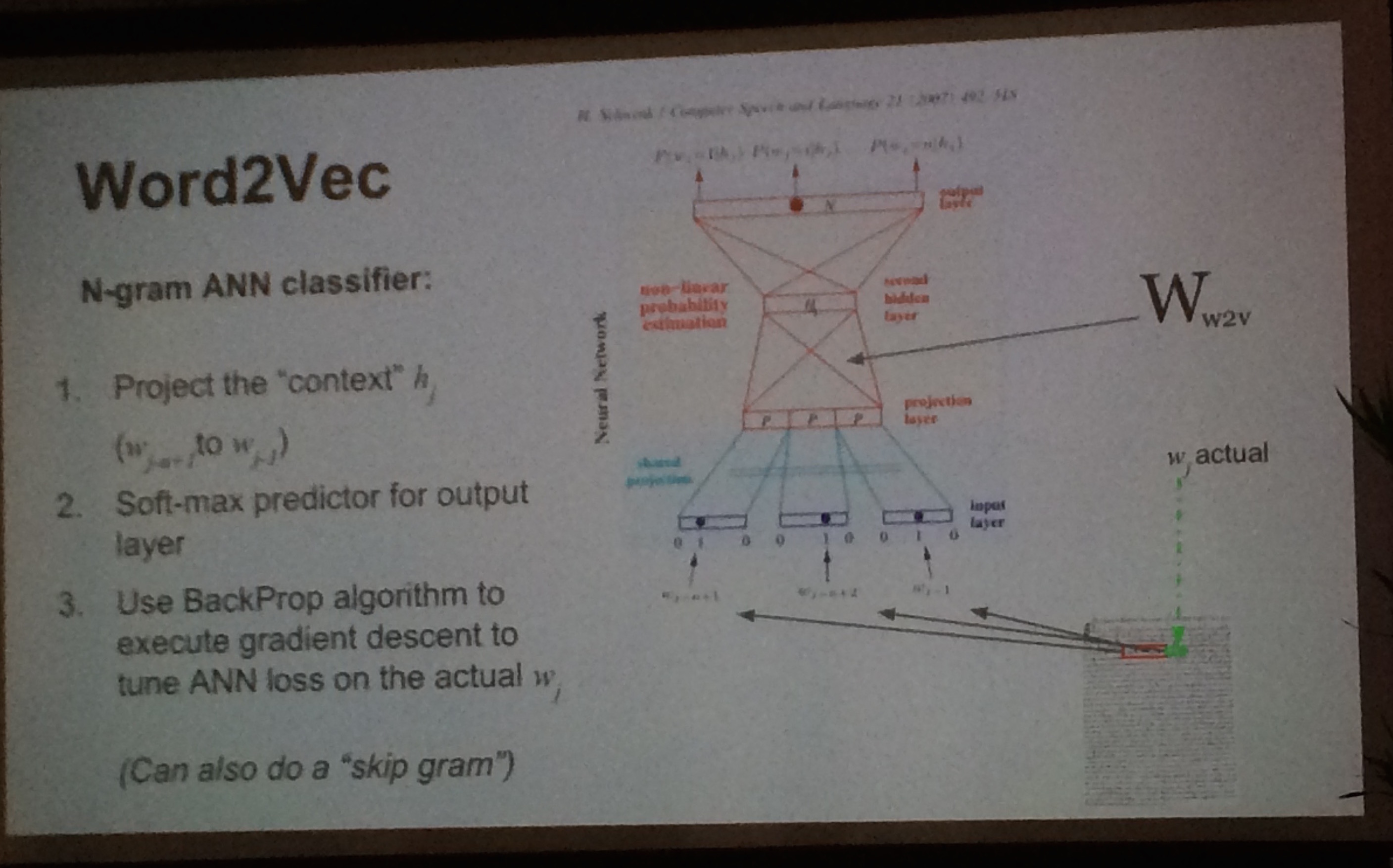
Fig 1. word2vec description slide from Mike Tamir.
2. Production-grade NLP is Spreading in Industry
For years, the most obvious users of natural language processing were those involved in search, tagging, sentiment on social graphs, and recommendations. And there are clear applications to voice recognition. What was most exciting to see at
#tbtb, however, were the companies making use of NLP in production for core product enhancements that stretched beyond traditional uses.
Sudeep Das gave a great talk about the places within
OpenTable where NLP is improving their customer’s experience in subtle but measurable ways. Creating topics around word embeddings of customer reviews they can get much richer insights about a restaurant than what appears in the metadata of that
restaurant's website. And in showing reviews they can then bias towards (longer) reviews that hit on all the important topics for that restaurant. Das showed an auto-discovered review for a restaurant (one of my favorites,
La Mar!) that spoke to specific famous dishes, the view of the Bay, and the proximity to the Ferry Building. Also impressive was that when the data science team discovered an explosion of
cauliflower-infused dishes in New York City (yes, that’s a thing apparently), the marketing team was then able to capitalize on the trend by sending out a timely email campaign.
One of my favorite talks was by Chris Moody from
Stichfix. The company sends 5 fashion items at a time to women. They send back what they don’t want. He showed how, using
word2vec, they are using user comments on their products coupled with buying behavior to enrich the suggestions of new items. These are then used by personal fashion consultants as an augmentative tool in their decisions of what to send next. They train the
word2vec embedding on the wikipedia corpus and argument that with training using existing reviews and comments.
(Note: both Sudeep and Chris are former astronomers, but that has little bearing on my glowing reviews of their talks!)
Fig. 2. Sudeep Das, "Learning from the Diner's Experience". Via Twitter. 3. Open tools are being used but probably not compensated in the way they should
For training models, a number of large open datasets and code are used by virtually everyone (including by us at
wise.io).
Freebase (“wikipedia for structured data”),
wikidata, and
common crawl were mentioned throughout the conference, in talks from folks at Crunchbase and
Klout for example. The most commonly used implementation of
word2vec is in the open-source
gensim project (with some growing interest in the
Spark implementation as well). Most of these projects are just scraping by without a stable source of funding, which seems ridiculous. It seems that few of these open data and software communities are compensated by the (large) corporations that use these tools. This is perfectly legal of course given the licensing but one wonders if there isn’t a better funding model for all of us to consider in the future (like at
bountysource).
4. "RNNs for X"
It’s an exciting time for deep learning and NLP, evidence throughout the conference but highlighted in the talk by
Richard Socher, a co-founder and CTO of MetaMind. Based on work he did with recursive neural networks at Stanford, Socher discussed how tree-based learning is performing exceedingly well on sentiment (recent work using Long Short-Term Memory Networks [
LSTM] here). Jeremy Howard, founder of Enlitic (using deep learning for medical diagnosis intelligence), discussed using recurrent neural nets to upend long-standing industries. In his panel discussion with Pete Skomoroch he touted the power of RNNs, likening this moment in history as the early days of the web when Internet + (anything) changed (anything) forever. Will RNN + (anything) disrupt (anything) again? We’ll see!Fig. 3. Richard Socher, "Deep Learning for Natural Language Processing"
5. A Big Problem: Massive Gender Imbalance
Out of 57 speakers and panelists who spoke at the conference, there was exactly
twofour (*) women,
Vita Markman and
Katrin Tomanek. In
two full days. I really don’t know how this is possible in a day and age where there are so many outstanding female machine learning experts and NLP practitioners (A
few of us had a mini-tweetstorm about this where a number of top female speakers in the Bay Area were named.) I don’t want to speculate as to why this happened at this particular conference but it’s clearly not a positive thing for anyone involved, including the sponsors and, frankly, the participants.
Charles Covey-Brandt (at
Disqus) has a great rule which is that he will refuse to serve on a panel or give a talk in a conference that does not achieve fair representation. If all of us did the same thing, conferences would be better off and we’d be done with this awful foolishness.
(*) Edit after original post: Alexy Khrabrov noted in the comments that two other women spoke at the conference, Diana Hu of Verizon and Katelyn Lyster. Neither are listed in the published schedule at
http://text.bythebay.io/schedule.html. So a total of 4 out of 59 spoke. Alexy also notes efforts that the organizers took to solicit broader participation.
That’s it for my wrap up summary. Feel free to comment if I missed anything important (or even not-so-important). Caveat: I attended both days but, given the multitrack talk schedule, I was unable to see all the talks.


)